

UGV Path Programming Based on the DQN With Noise in the Output Layer
-
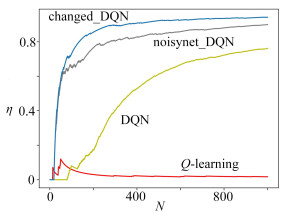
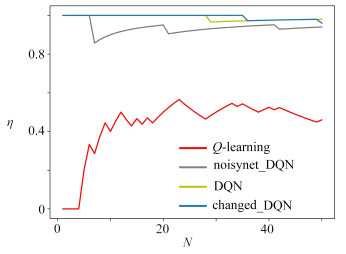
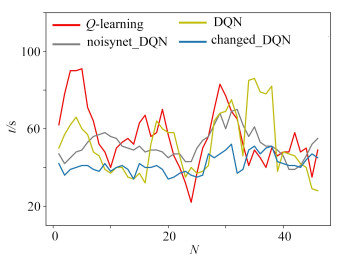
摘要: 在DQN算法的框架下,研究了无人车路径规划问题.为提高探索效率,将处理连续状态的DQN算法加以变化地应用到离散状态,同时为平衡探索与利用,选择仅在DQN网络输出层添加噪声,并设计了渐进式奖励函数,最后在Gazebo仿真环境中进行实验.仿真结果表明:①该策略能快速规划出从初始点到目标点的无碰撞路线,与Q-learning算法、DQN算法和noisynet_DQN算法相比,该文提出的算法收敛速度更快;②该策略关于初始点、目标点、障碍物具有泛化能力,验证了其有效性与鲁棒性.Abstract: The path programming of the unmanned ground vehicle (UGV) was studied under the framework of the deep Q-network (DQN) algorithm. To improve the exploration efficiency, the DQN algorithm was applied through discretization of the continuous state into the discrete state. To balance between exploration and exploitation, the Gaussian noise was added only in the output layer of the network, and a progressive reward function was designed. Finally, experiments were carried out in the Gazebo simulation environment. The simulation results show that, first, this strategy can quickly program a collision-free route from the initial point to the target point, and the convergence speed is significantly higher than those of the Q-learning algorithm, the DQN algorithm and the noisynet_DQN algorithm; second, this strategy has the generalization ability about the initial point, the target point and the obstacles, as well as verified effectiveness and robustness.
-
Key words:
- deep reinforcement learning /
- UGV /
- DQN algorithm /
- Gaussian noise /
- path programming /
- Gazebo simulation
-

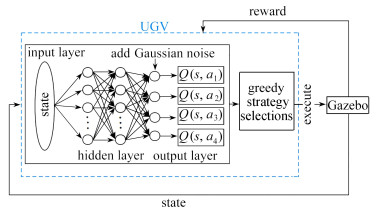
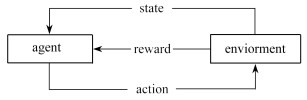
图 3 在输出层添加噪声的DQN算法框架
Figure 3. The DQN algorithm framework for adding noise in the output layer

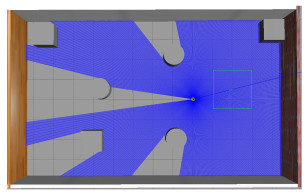
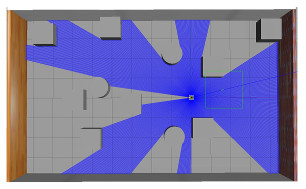
图 4 Gazebo仿真环境
注 为了解释图中的颜色,读者可以参考本文的电子网页版本,后同.
Figure 4. The Gazebo simulation environment

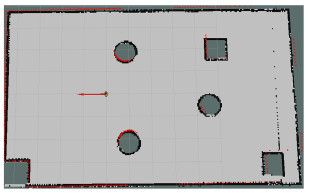
图 5 Rviz仿真环境
注 为了解释图中的颜色,读者可以参考本文的电子网页版本,后同.
Figure 5. The Rviz simulation environment

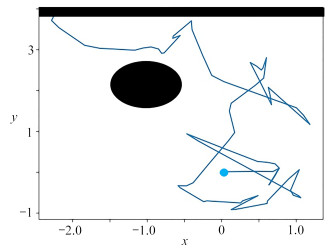
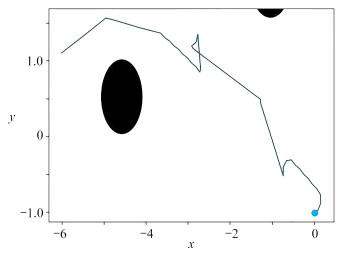
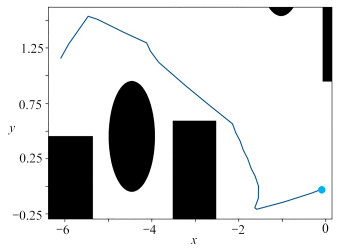
图 13 目标点改变时changed_DQN算法路径规划效果图
Figure 13. Path programming effects based on changed_DQN with changing target point

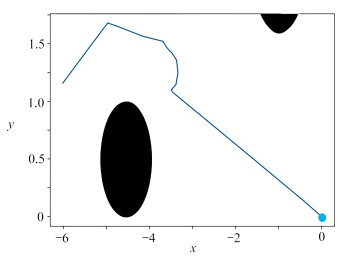
图 14 起始点改变时changed_DQN算法路径规划效果图
Figure 14. Path programming effects based on changed_DQN with changing starting point

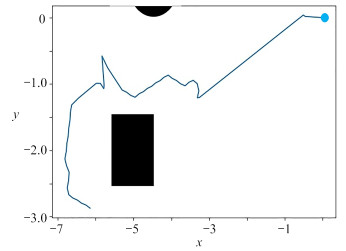
图 15 障碍物改变后的changed_DQN算法路径规划效果图
Figure 15. Path programming effects of changed_DQN after the obstacle change

图 16 障碍物改变后的Gazebo仿真环境
Figure 16. The Gazebo simulation environment after the obstacle change
表 1 算法训练参数
Table 1. Algorithm training parameters
parameter meaning value α learning rate 0.001 γ discount factor 0.9 M memory length 1 000 m batch size during training 100 E training number 1 000 dt /m target point threshold 0.25 do /m obstacle threshold 0.15  下载: 导出CSV
下载: 导出CSV
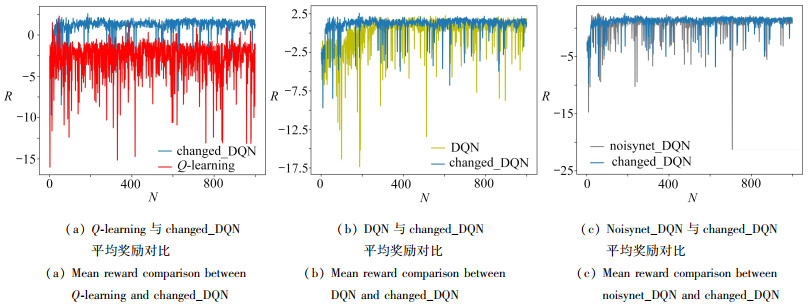
表 2 平均奖励的均值与方差
Table 2. The mean and variance of the mean rewards
changed_DQN noisynet_DQN DQN Q-learning mean 1.081 32 0.707 14 0.091 377 8 -2.808 89 variance 1.460 35 3.299 63 4.695 35 5.056 47
下载: 导出CSV
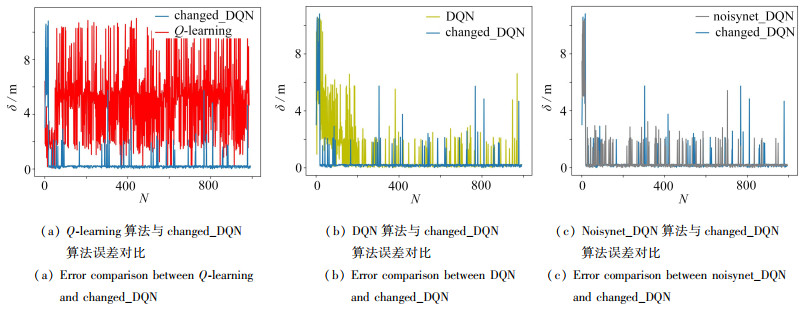
表 3 误差的均值与方差
Table 3. The mean and variance of the errors
changed_DQN noisynet_DQN DQN Q-learning mean 0.379 32 0.454 48 0.873 16 4.911 19 variance 1.120 79 1.213 50 2.741 73 6.128 13
下载: 导出CSV
-
[1] 王洪斌, 尹鹏衡, 郑维, 等. 基于改进的A*算法与动态窗口法的移动机器人路径规划[J]. 机器人, 2020, 42(3): 346-353. https://www.cnki.com.cn/Article/CJFDTOTAL-JQRR202003010.htmWANG Hongbin, YIN Pengheng, ZHENG Wei, et al. Mobile robot path planning based on improved A* algorithm and dynamic window method[J]. Robot, 2020, 42(3): 346-353. (in Chinese) https://www.cnki.com.cn/Article/CJFDTOTAL-JQRR202003010.htm [2] SONG Q, LI S, ZHE L. Automatic guided vehicle path planning based on improved genetic algorithm[J]. Modular Machine Tool and Automatic Processing Technology, 2020(7): 88-92. [3] ZHANG S, PU J, SI Y, et al. Review on the application of ant colony algorithm in path planning of mobile robots[J]. Computer Engineering and Applications, 2020, 56(8): 10-19. [4] KOVÁCS B, SZAYER G, TAJTI F. A novel potential field method for path planning of mobile robots by adapting animal motion attributes[J]. Robotics and Autonomous Systems, 2016, 82: 24-34. doi: 10.1016/j.robot.2016.04.007 [5] 马丽新, 刘晨, 刘磊. 基于actor-critic算法的分数阶多自主体系统最优主-从一致性控制[J]. 应用数学和力学, 2022, 43(1): 104-114. doi: 10.21656/1000-0887.420124MA Lixin, LIU Chen, LIU Lei. Optimal leader-following consensus control of fractional-order multi-agent systems based on the actor-critic algorithm[J]. Applied Mathematics and Mechanics, 2022, 43(1): 104-114. (in Chinese) doi: 10.21656/1000-0887.420124 [6] 刘晨, 刘磊. 基于事件触发策略的多智能体系统的最优主-从一致性分析[J]. 应用数学和力学, 2019, 40(11): 1278-1288. doi: 10.21656/1000-0887.400216LIU Chen, LIU Lei. Optimal leader-following consensus of multi-agent systems based on event-triggered strategy[J]. Applied Mathematics and Mechanics, 2019, 40(11): 1278-1288. (in Chinese) doi: 10.21656/1000-0887.400216 [7] CHEN Y F, LIU M, EVERETT M, et al. Decentralized non-communicating multiagent collision avoidance with deep reinforcement learning[C]//2017 IEEE International Conference on Robotics and Automation. Singapore, 2017: 285-292. [8] 高阳, 陈世福, 陆鑫. 强化学习研究综述[J]. 自动化学报, 2004, 30(1): 86-100. https://www.cnki.com.cn/Article/CJFDTOTAL-MOTO200401010.htmGAO Yang, CHEN Shifu, LU Xin. A review of reinforcement learning[J]. Journal of Automatica Sinica, 2004, 30(1): 86-100. (in Chinese) https://www.cnki.com.cn/Article/CJFDTOTAL-MOTO200401010.htm [9] YUAN X. faster finding of optimal path in robotics playground using Q-learning with "exploitation-exploration trade-off"[J]. Journal of Physics: Conference Series, 2021, 1748(2): 022008. doi: 10.1088/1742-6596/1748/2/022008 [10] MAOUDJ A, HENTOUT A. Optimal path planning approach based on Q-learning algorithm for mobile robots[J]. Applied Soft Computing Journal, 2020, 97(A): 106796. [11] 张宁, 李彩虹, 郭娜, 等. 基于CM-Q学习的自主移动机器人局部路径规划[J]. 山东理工大学学报(自然科学版), 2020, 34(4): 37-43. https://www.cnki.com.cn/Article/CJFDTOTAL-SDGC202004007.htmZHANG Ning, LI Caihong, GUO Na, et al. Local path planning of autonomous mobile robot based on CM-Q learning[J]. Journal of Shandong University of Technology (Natural Science), 2020, 34(4): 37-43. (in Chinese) https://www.cnki.com.cn/Article/CJFDTOTAL-SDGC202004007.htm [12] 张福海, 李宁, 袁儒鹏, 等. 基于强化学习的机器人路径规划算法[J]. 华中科技大学学报(自然科学版), 2018, 46(12): 65-70. https://www.cnki.com.cn/Article/CJFDTOTAL-HZLG201812012.htmZHANG Fuhai, LI Ning, YUAN Rupeng, et al. Robot path planning algorithm based on reinforcement learning[J]. Journal of Huazhong University of Science and Technology (Natural Science Edition), 2018, 46(12): 65-70. (in Chinese) https://www.cnki.com.cn/Article/CJFDTOTAL-HZLG201812012.htm [13] 王沐晨, 李立州, 张珺, 等. 基于卷积神经网络气动力降阶模型的翼型优化方法[J]. 应用数学和力学, 2022, 43(1): 77-83. doi: 10.21656/1000-0887.420137WANG Muchen, LI Lizhou, ZHANG Jun, et al. An airfoil optimization method based on the convolutional neural network aerodynamic reduced order model[J]. Applied Mathematics and Mechanics, 2022, 43(1): 77-83. (in Chinese) doi: 10.21656/1000-0887.420137 [14] 高普阳, 赵子桐, 杨扬. 基于卷积神经网络模型数值求解双曲型偏微分方程的研究[J]. 应用数学和力学, 2021, 42(9): 932-947. doi: 10.21656/1000-0887.420050GAO Puyang, ZHAO Zitong, YANG Yang. Study on numerical solutions to hyperbolic partial differential equations based on the convolutional neural network model[J]. Applied Mathematics and Mechanics, 2021, 42(9): 932-947. (in Chinese) doi: 10.21656/1000-0887.420050 [15] MNIH V, KAVUKCUOGLU K, SILVER D, et al. Playing Atari with deep reinforcement learning[Z/OL]. 2013[2022-03-07]. https://arxiv.org/abs/1312.5602 .[16] 董永峰, 杨琛, 董瑶, 等. 基于改进的DQN机器人路径规划[J]. 计算机工程与设计, 2021, 42(2): 552-558. https://www.cnki.com.cn/Article/CJFDTOTAL-SJSJ202102038.htmDONG Yongfeng, YANG Chen, DONG Yao, et al. Robot path planning based on improved DQN[J]. Computer Engineering and Design, 2021, 42(2): 552-558. (in Chinese) https://www.cnki.com.cn/Article/CJFDTOTAL-SJSJ202102038.htm [17] 姜兰. 基于强化学习的智能小车路径规划[D]. 硕士学位论文. 杭州: 浙江理工大学, 2019.JIANG Lan. Intelligent car path planning based on reinforcement learning[D]. Master Thesis. Hangzhou: Zhejiang Sci-Tech University, 2019. (in Chinese) [18] 丁志强. 基于Q学习算法的快速避障路径规划方法研究[D]. 硕士学位论文. 大连: 大连理工大学, 2021.DING Zhiqiang. Research on fast obstacle avoidance path planning method based on Q-learning alorithm[D]. Master Thesis. Dalian: Dalian University of Technology, 2021. (in Chinese) [19] FORTUNATO M, AZAR M G, PIOT B, et al. Noisy networks for exploration[Z/OL]. 2018[2022-03-07]. https://arxiv.org/abs/1706.10295.pdf .[20] 胡刚. 基于强化学习的无地图搜索导航[D]. 硕士学位论文. 哈尔滨: 哈尔滨工业大学, 2019.HU Gang. Mapless exploration navigation based on reinforcement learning[D]. Master Thesis. Harbin: Harbin Industrial University, 2019. (in Chinese) [21] 王健, 赵亚川, 赵忠英, 等. 基于Q(λ)-learning的移动机器人路径规划改进探索方法[J]. 自动化与表, 2019, 34(11): 39-41. https://www.cnki.com.cn/Article/CJFDTOTAL-ZDHY201911013.htmWANG Jian, ZHAO Yachuan, ZHAO Zhongying, et al. Improved exploration method for mobile robot path planning based on Q(λ)-learning[J]. Automation and Instrument, 2019, 34(11): 39-41. (in Chinese) https://www.cnki.com.cn/Article/CJFDTOTAL-ZDHY201911013.htm [22] 吴夏铭. 基于深度强化学习的路径规划算法研究[D]. 硕士学位论文. 长春: 长春理工大学, 2020.WU Xiaming. Research on path planning algorithm based on deep reinforcement learning[D]. Master Thesis. Changchun: Changchun University of Science and Technology, 2020. (in Chinese) [23] 吴俊塔. 基于集成的多深度确定性策略梯度的无人驾驶策略研究[D]. 硕士学位论文. 深圳: 中国科学院深圳先进技术研究院, 2019.WU Junta. Research of unmanned driving policy based on aggregated multiple deterministic policy gradient[D]. Master Thesis. Shenzhen: Shenzhen Institute of Advanced Technology, Chinese Academy of Sciences, 2019. (in Chinese) [24] 于乃功, 王琛, 默凡凡, 等. 基于Q学习算法和遗传算法的动态环境路径规划[J]. 北京工业大学学报, 2017, 43(7): 1009-1016. https://www.cnki.com.cn/Article/CJFDTOTAL-BJGD201707006.htmYU Naigong, WANG Chen, MO Fanfan, et al. Dynamic environment path planning based on Q-learning algorithm and genetic algorithm[J]. Journal of Beijing University of Technology, 2017, 43(7): 1009-1016. (in Chinese) https://www.cnki.com.cn/Article/CJFDTOTAL-BJGD201707006.htm [25] 周翼, 陈渤. 一种改进dueling网络的机器人避障方法[J]. 西安电子科技大学学报, 2019, 46(1): 46-50. https://www.cnki.com.cn/Article/CJFDTOTAL-XDKD201901010.htmZHOU Yi, CHEN Bo. Method for obstacle avoidance based on improvement dueling Networks[J]. Journal of Xidian University, 2019, 46(1): 46-50. (in Chinese) https://www.cnki.com.cn/Article/CJFDTOTAL-XDKD201901010.htm -
计量
- 文章访问数: 737
- HTML全文浏览量: 292
- PDF下载量: 68
- 被引次数: 0

 渝公网安备50010802005915号
渝公网安备50010802005915号